
During my first year of postgrad, almost a decade ago, I developed one of the most valuable habit I’ve developed in my life.
Every Monday morning, sitting in an empty university library, me and a good friend of mine, would pick one paper out of a stack of printed publication. We would then give ourselves the entire week to understand the content, and on Friday, we would debrief it together. We kept a backlog of publications and, every time we stumbled upon an interesting topic, we would pick a publication to deep dive into it.
In less than a semester, we developed a systematic approach to reading scientific literature, navigate through dependencies and previous knowledge, but most important, we were learning how to deep focus into a very specific topic in a limited amount time. The part that I appreciated the most was the journey from being completely clueless, staring at hieroglyphic formulas on a Monday morning, to write those very formulas and explaining how they worked on a Friday afternoon.
One of 2017’s resolutions was to go back, in a systematic way, to that habit. A very hard beginning, with a lot of frustration and brain fatigue, soon left space to a gratifying momentum.
2017 has been a rich year for the scientific community orbiting around computer science.
The ML trend is growing strong and more companies are publishing as a mean to attract top industry talents and strengthen their position as innovators.
I read from cryptography to computer vision, quite often falling back on my favorite topics like data infrastructure, machine learning and music information retrieval.
After 28 papers crunched in the last year, and at least other 30 dropped in the process, here some of my favorite.
An efficient bandit algorithm for realtime multivariate optimization
Hill et al. – Amazon
Found looking through KDD’17 submissions
You just entered in a casino, in front of you 4 slots machines, all different from each other.
This is your chance to get rich. With your bucket full of coins you get closer, not sure which one to start with.
After a moment of uncertainty you go for the second slot machine from the left.
Insert the first coin, and pull the level.
You lose.
You try 2 more time before you finally win. You feel the rush of excitement, and here the 4th coin goes, and again, another win. This slot machine must be a very good one – you think – I’ll stick with it. You are in what is technically called exploitation mode. Your confidence in having found the right machine makes you stick to it.
Unfortunately your next 50 tries are not as successful as you were expecting.
You finally decide to give up on slot machine #2, and slide to the right to slot machine #3. Couple of tries are unsuccessful and in full despair you slide right right, to slot machine #4. Now you are in exploration mode, fast changing from one slot machine to another, in order to get a sense which one is more likely to give the highest reward.
You just learned 2 important lessons. ‘The house always win’ and how complex is to create a strategy that balance exploration and exploitation in an unknown environment.
Too little exploration and you may be stuck with the wrong slot machine, to much exploration may result in loss of rewards you could have collected if only you spent a little bit more time on ‘that’ slot machine.
You are trying to define the best way to play the 4 slot machines, colorfully called multi-armed bandits, in a way that, at the end of the day, you get out of the casino richer than you were when you entered.
What you just read is an oversimplified formulation of the multi-armed bandit problem.
The Multi-Armed Bandit problem at first seems very artificial, something only a gamer or a statistician would love.
Truth is, there are plenty of real world applications.

Let’s assume we have a ‘recommended products’ widget, as part of a search result page.
Those 4 products displayed should not simply ranked by performance metrics. Just displaying the most purchased or viewed one, will increase the survival bias – the more you see them the more you buy them – missing-out on new, maybe better, products. We want to avoid pure exploitation.
Assuming we have 50 candidate products, trying all the possible permutation, 5 527 200 (50x49x48x47) in total, will take an incredible amount of time if done via A/B testing, leading to a very expensive exploration.
We want instead determine a strategy to quickly converge to high performing product given each and every search query, potentially personalized for the user and aware of his/her current context/needs.
If your option space change dynamically, in our case assuming there is a new editorial playlist feature Timberlake’s song, this approach, through continue online evaluation, allow to quickly rule out if the new playlist has an high reward or not, compared to all the others we already evaluated.
In An efficient bandit algorithm for real-time multivariate optimization, Hill et al, present how they solved the problem at Amazon, including a hill-climbing greedy heuristic for realtime selection and a model that accounts for inter-object optimizations. In plain english, we want to move away from solutions that are not performing well as fast as possible, and at the same time recognize that two products, are a great match when displayed close to each other, even if we see them appearing the first time in different permutations.
Amazon reports to have increased by 21% the conversion rate on one of their check out page thanks to this technique.
If you are in front of a multivariate optimization problem, and the volume of your users makes A/B testing too slow, this paper should be on your read list.
The Multi-armed bandit is part of the reinforcement learning (RL) algorithm family, given his online/realtime nature. The reference section of the paper is a golden mine of everything you need to know to grasp everything that happened in the field constraint programming and linear optimization in the last 60 years that led to some of todays successful RL applications.
If you want to know more on the topic Algorithms for Reinforcement Learning and the evergreen Artificial Intelligence: A Modern Approach.
A dirty dozen: twelve common metric interpretation pitfalls in online controlled experiments
Dmitriev et al. – Microsoft
This is another paper part from the KDD’17 submission pool.
I felt in love with this paper for two reasons: the effective delivery and the transparent way the Microsoft team articulates and shares their company’s mistakes.
In the first part we are introduced to the type of metrics involved in assessing A/B testing across multiple product, from Skype to Bing, from XBox to Office.
It then moves into listing twelve common pitfalls, including recent ‘incidents’ of facilitate the understanding of how easy is to be tricked into drawing the wrong conclusion.
Among the twelve, there is one pitfall that sounded dangerously familiar.
Assuming Underpowered Metrics had no change
The total number of page views per user is an important metric in experiments on MSN.com. In one MSN.com experiment, this metric had a 0.5% increase between the treatment and control, but the associated p-value was not statistically significant.
As you can probably imagine, 0.5% on such a metric (page view) is quite an eventful result, should the lack of statistically significant make us discard such result?
The paper explain how that experiment was setup to not have enough statistical ’Power’. Power is the probability of rejecting the null hypothesis given that the alternative hypothesis is true. Having a higher power implies that an experiment is more capable of detecting a statistically significant change when there is indeed a change.
Back to our example, Microsoft could not concluded that the treatment was introducing an improvement, but at the same time could not conclude that the treatment was ineffective either.
It is very important to keep this in mind every time we see an A/B test coming back inconclusive.
To avoid the aforementioned issues, a priori power analysis should be conducted to estimate sufficient sample sizes. The harder is to impact a metric, the bigger should be sample size. Bing, for instance, runs experiment on a 10% population sample per treatment to make sure their experiments are actionable.
The paper goes on, with other 11 examples, and very detailed use cases.
A huge thank to Microsoft for sharing their hard-won experiences.
This is golden material for everyone running experiments or taking decision upon A/B testing results.
For someone like me, knowing that even a company like Microsoft, famous for its humongous investment in the space, walk the fine line of misjudgment on a regular basis, is an important confirmation of how hard is to be truly data driven.
If you are interested in the topic, here a masterful presentation that Ron Kohavi, well known principle scientist at Microsoft, gave at KDD in 2015
TFX: A TensorFlow-Based Production-Scale Machine Learning Platform
Baylor et al. – Google
Usually it ends up in me narrating the normal day in life of a Googler and going through the tools used in the making of billion-user-scale software.
From ‘Perforce’ handling over 50000 engineers working on the same repo to Blaze orchestrating builds and dependencies. All the nice integrated software aimed to increase developer productivity as well as infrastructure that ‘simply works’ and offers everything you exactly need.
When it comes to ML, no surprise, Google is years ahead of the competitors. Even now that they are more involved in the OSS community, it still represent a small portion of what is available internally. Under this perspective, TensorFlow, today most used library for machine learning, is just the tip of the iceberg of the set of tools and libraries available in big G.
In this paper, Google gives you a glimpse into the journey of building and running a ML production system at scale.
Today, the majority of resources and conversation around ML are focused on a very small component of the entire process. The Training part. However if you want to reliably deploy ML in production and scale you need to do much more than that. For example, even in the most basic production scenario , you’d want to make sure your model doesn’t train on corrupted data, and only high quality models are pushed to production. Both those validation steps are important to make sure you are avoid bad user experience and server disruptions.
In the past, Google built different systems for each of the learning algorithm adopted in the company. The most used systems were supporting either Linear or Neural Networks models.
As explained in this paper, a year ago, Google took a step forward, unify their systems into one platform.
Through the presentation of the anatomy of a general-purpose machine learning platforms, the Google team introduces TFX, an implementation of such platform around TensorFlow, supporting among other feature continuous training and serving with production-level reliability.
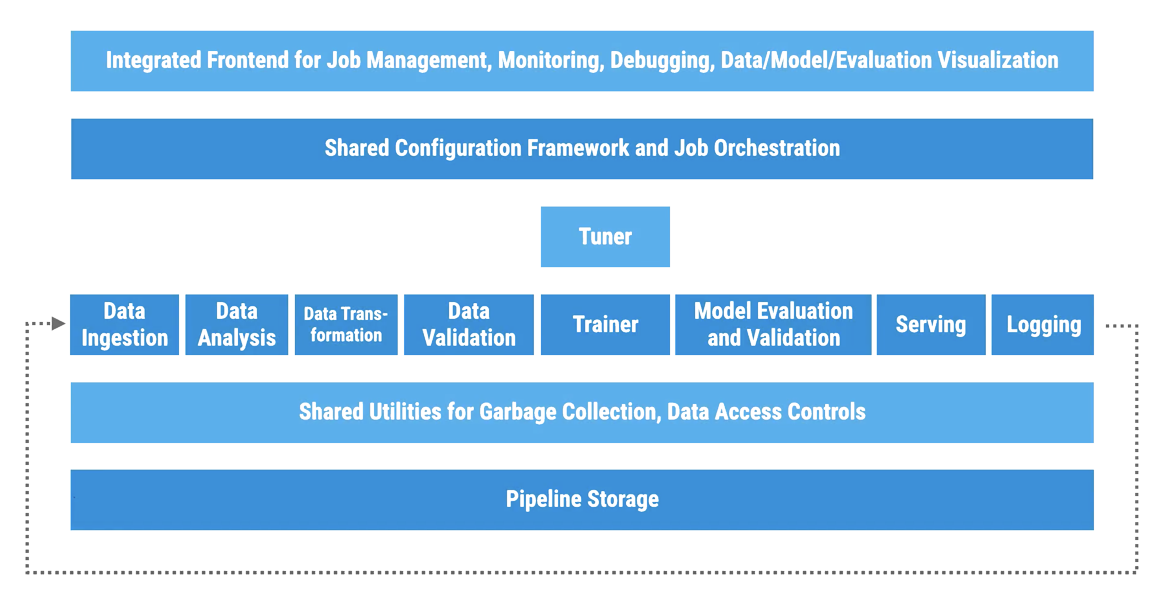
It’s clear how much thinking has been poured into this architecture, especially in regards of the orchestration layer, usually implemented with glue code and custom scripts.
This paper should be the starting point for everyone interest in building a ML platform, and I see a lot of the learnings reflect in similar implementation in the industry (Uber’s Michelangelo among all). And if you feel amazed by the quality of Google’s work, just keep in mind, that by the time this paper was out, it is probably already 1-2 year obsolete.
This is how it feels to be a ML engineer at Google.
Learning from Simulated and Unsupervised Images through Adversarial Training
Ashish Shrivastava et al. – Apple
I’m cheating a bit with this one.
This paper was first published in December 2016, and later revised in July 2017.
The paper describes a technique for improve image recognition training using computer-generated images rather than real-world images.
In machine learning, using synthetic media (like images from a video game) to train neural networks can be more efficient than using real-world images. That’s because synthetic image data is already labeled and annotated, while real-world image data requires somebody to exhaustively label everything. The paper proposed an adversarial approach (GAN has been indeed of the hottest topic in the field in 2017) using synthetic images as an input, in contrast with the standard approach of using random vectors, to predict real images.
The approach outlined attempts to bridge the Supervised and Unsupervised worlds. The paper is well written and rich of insightful details.
The paper’s lead author is Apple’s head of multimedia research Ashish Shrivastava, known in the Multimedia Information retrieval field for his work at the University of Maryland research center. The other Apple employees listed as co-authors where co-founders of an AI startup that assessed a person’s emotions by looking at facial expressions called Emotient, which Apple acquired in 2016.
Apple’s first AI paper marks a major step for the company.
For years, the AI research community has been critical of Apple’s secretiveness. Its secrecy has even hurt the company’s recruiting efforts for AI talent. The move towards more openness with the community is important for Apple as the push for more advanced AI software spreads across the tech industry.
I saluted this as the first attempt to Apple to share more, effort that continued throughout 2017 on their dedicated website
An efficient bandit algorithm for realtime multivariate optimization
A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments
TFX: A TensorFlow-Based Production-Scale Machine Learning Platform
Learning from Simulated and Unsupervised Images through Adversarial Training
Here some of my favorite places to keep myself updated on new publications:
The Morning Paper
Two Minutes Paper
MIT Distributed System Reading Group
MIT AI publications
Best Paper award in Computer Science
As well as companies’ research portals like the Google, Facebook and Microsoft one.